

Numlock Awards: Final Oscar Predictions
The Oscars are engineered to be impossible to predict
The Numlock Awards Supplement is your one-stop awards season update. You’ll get two editions per week, one from Not Her Again’s Michael Domanico breaking down an Oscar contender or campaigner and taking you behind the storylines, and the other from Walt Hickey looking at the numerical analysis of the Oscars and the quest to predict them. If you’re just joining us, catch up on everything this season by checking out this post. Today’s edition comes from Walter.
All the final predictions are down below! Thanks so much for following along with us this Oscar season. First up, a brief essay on Oscar predicting!
The Oscars are engineered to be impossible to predict.
I’ve spent lots of time this year seriously thinking about the absolute baseline of what exactly an Oscar model needs to do. At the end of the day, an Oscar model has to listen, because the nature of the medium means that all our usual techniques of understanding and quantifying competition do not apply. When movies work well — when they’re the empathy machines that successfully move audiences — we don’t actually know why. As a result, they’re inherently resistant to quantification.
You can quantify a movie as a product through box office, but movies are reduced to financial instruments merely as a matter of practicality.
You can pretend that the plural of “critic” is “legislature” and pretend the point of art is to satisfy a plurality of particularly pasty white men, but it’s not and it isn’t.
You can analyze the mechanics or the sinew of a film — screen time or lines or keywords or shots or actions per minute or per character or per actor — and still come away lacking, as if someone could read the nutrition facts and claim to understand why people like Coca-Cola.
Movies are hard, and at their very nature immune from the terrestrial techniques that help a person be good at blackjack. So setting that aside — the whole platonic nature of art and mankind’s inability to understand why some things make their dumb brains squirt dopamine and other things don’t — how do we predict this damn thing? An Oscar model effectively has to capture a lot of indicators that motion in the direction of preference. The reasons that people vote for what they vote for are far too stupid and vain to simulate. So we have to think about not what makes a movie Good, but what makes a movie a Winner.
Because here’s the truth: the fundamental gap between what is good and what is a winner is literally the entire crux of awards coverage. It is a time of year where entertainment writers realize that the ape part of our brain is not merely ready but enthusiastic to sort into tribes despite an overwhelming similarity of interest.

To accomplish that, I’ve seriously drilled down further than I have before into who exactly makes up the Academy and what we should be thinking about when we look to precursors. This led to some serious overhauls! I completely re-did which critics’ awards are actually important. I stripped the automatic qualifier status from the Los Angeles, New York, Chicago, National Board of Review and Satellite critics’ prizes, and opened it up so any regional critics’ group that is actually trying to pick the Best Picture winners can break in regardless of municipal size. I cranked up the importance of recent predictions and diminished the impact of historical correlation the further back you go. I rolled out the beta model in an attempt to, for the first time, factor in the weird way the Academy works.
The reason for that was because the model had begun to separate from the reality. The big city critics’ prizes aren’t trying to predict the Oscars. The Academy’s composition has fundamentally shifted in the past five years so the importance of the 1998 awards doesn’t mean jack compared to the 2008 awards or the 2018 season. The voting methodology the Academy introduced following the original model’s design has proven to be more consequential than originally believed, and I’d argue it was fairly important in the Moonlight and Spotlight wins.
Acknowledging that, here’s who I think is going to win Oscars based on the precursors:
Best Actor
I feel really good with a Rami Malek prediction. On paper, he’s got it all — a campaign that seems to be working, effective management of possible directorial-based arguments against the performance, and a role that seriously speaks to the living person he sought to embody. Convincing both SAG and BAFTA pretty much ties this one together, and the early win at the Golden Globes actually means something in this category. A loss for Malek would cause a fairly substantial correction to the Best Actor weighting, as the stars are basically aligned for him.

Best Actress
This category still has some chaos in it — the Actress campaigns have been gnarlier than the Actor campaigns by a mile this year — and Colman’s win at BAFTA and Gaga’s win at the Critics’ Choice (tying with Close) are reasons enough to go into Oscar night with a little uncertainty. But at the end of the day, Close won big when Close needed to. The win at SAG is major. If anything, the Academy is looking more like the (diverse, contains women) SAG than the other guilds, so their assent is a reason to be confident here. Remember that when we get to Supporting Actress. I’d be pretty surprised if Close lost.

Best Director
The DGA winner going on to win the Best Director Oscar, when possible, is as close to an Oscar lock as you can ask for. Aiding our confidence here is that Alfonso Cuarón also won almost every other possible award in this model. Cuarón failing to pull off the finish after an awards season sweep is difficult to conceive.

Best Picture
The Writers had mercy on us and rewarded two un-nominated films with the WGA prizes. As such, the outcomes are unchanged from post-BAFTA and after we did the Oscar vote simulations. Right now, Roma looks really good.

And here’s the simulation model run, just to remind everyone:
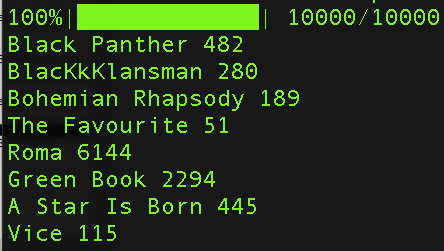
I’ve written a lot about this already — I believe that the New Academy has the votes to significantly influence Best Picture but I also believe that this year was not the year that a film capitalized on that math — but in general here’s where our model stands with various wins and losses. This is a really great year for Oscar predicting because there’s a fairly wide spread of outcomes that will heavily influence our weighting moving forward. So getting it wrong this year — which is totally plausible — would still do a lot to aid us in getting closer to what precursors are better or worse than others. It’s like comparing the Moonlight year, when the moral was “all these precursors screwed up,” with the Spotlight year, when at least we were able to conclude that the SAG did better than the BAFTA, DGA, and PGA.
So hey, a Roma loss just means we’re that much better off next year. A difficult year to forecast, but we’ll get a whole lot out of it no matter the outcome.
Best Supporting Actor
This is what a sweep looks like. Mahershala Ali has crushed it at every possible stage of the Oscar race, and a loss would basically just mean that we’re less confident in Supporting Actor precursors moving forward.

Best Supporting Actress
This is the hardest category of the year! Flukes of nominations left an early front-runner entirely out of the mix when it came to the two most important awards we track, with BAFTA and SAG not nominating If Beale Street Could Talk’s Regina King. It’d be one thing if those awards gave a clear indication of who’d rise up to challenge King. And while the BAFTA did reward Rachel Weisz, that could be a home-field advantage situation. The reality that the overwhelmingly predictive SAG declined to honor Weisz, Adams or Stone is another puzzle.
Either way, this category will be by far the biggest lessons learned of the 91st Oscars. The SAG is going to take a predictive hit. Now it’s basically critics vs. British. A King win shows that the Globes, Critics’ Choice, and an overwhelming majority of regional critics are enough to get a campaign past the finish line. A Weisz win shows that a mere BAFTA can render all that early season success moot. An Adams, Stone or de Tavira win shows that this category’s precursors are losing their mojo.

Have a great night everyone! Be sure to check out Michael’s full, 24-category ballot and guest columnist’s James England’s own model results before making your final picks in your office pool. We’ll have a post-mortem tomorrow. Thanks so much for reading!