Numlock Awards: Predicting Best Picture
The Numlock Awards Supplement is your one-stop awards season update. You’ll get two editions per week, one from Not Her Again’s Michael Domanico breaking down an Oscar contender or campaigner and taking you behind the storylines, and the other from Walt Hickey looking at the numerical analysis of the Oscars and the quest to predict them. Look for it in your inbox on Saturday and Sunday. If you’re just joining us, catch up on everything this season by checking out this post. Today’s edition comes from Walter.
Next week we’ll have a guest column from my friend James England! James has a fun Oscar model that really plays off the ranked preference voting system, but to get a good result he needs the input and vote of Oscar fans. Check it out here.
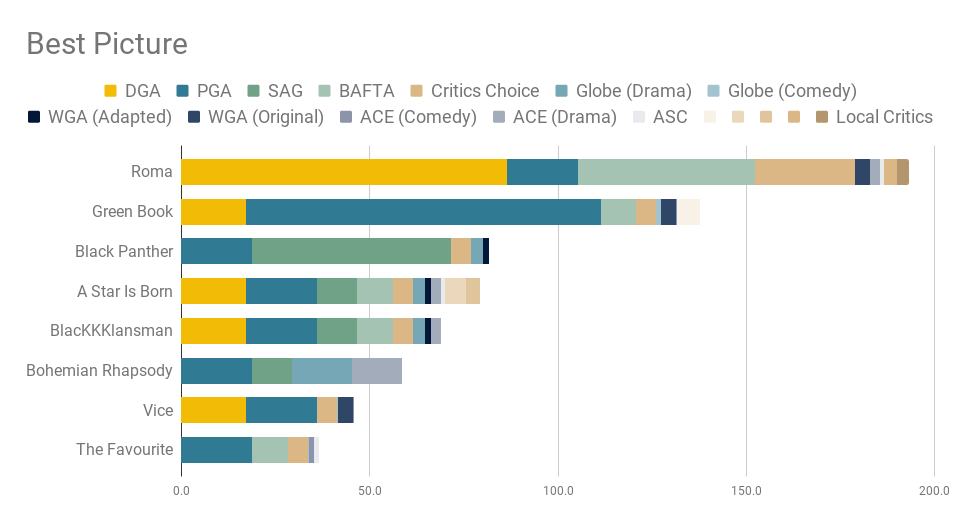
We know the general lay of the land for Best Picture. We know Roma had a really good early season and a robust late surge, we know that Black Panther and Green Book had solid hits in the middle there. And all that gives us is a very good look at the general attitudes the industry has toward the Oscar nominees. What we don’t have though is a way to reconcile those attitudes with the actual practicalities of voting. Oscar voting isn’t as simple as, say, a local mayor race. It’s not “whoever gets the most votes wins.” The Academy uses ranked preference voting to determine a best picture winner, where voters rank their favorite movies 1 to 8 and then the Academy goes through a counting process to determine a winner.
This week, I want to talk about what I’m calling the Beta model, where I use the data we get from the primary model to illustrate what makes that vote-counting process cool and unique.

Here’s how it works. When you hear FiveThirtyEight saying, “Candidate A has a 76 percent chance of winning their election,” what that actually means is that they gathered a lot of data about the election, they figured out the likelihood of possible outcomes, they did 1,000 simulations, and they found that in 760 of those 1,000 simulations, the candidate won.
We’re doing a similar procedure for Best Picture. If you want to just read the code, I put it all here, but I’m going to explain this for laymen so don’t get spooked and bear with me.
The gist is like this:
Simulate Best Picture preference weights for a voter
Simulate that voter’s ballot
Do that 8,800 times to simulate the Academy ballot box
Figure out who wins that simulation based on the rank preference algorithm
Do this 10,000 times. Report how many of those times each movie won
So, let’s get this going.
Simulate Best Picture preference weights for a voter

People like what they like for lots of different reasons, and every voter is different. If everyone had the same set of preferences, the Oscars would be boring. So we need to find a way to both integrate what we know about the Oscars preference orderings (through precursors) with the fundamentally wild number of reasons people like what they like.
Here’s how we do it.
We start with those scores each movie accumulated over the course of the precursor season. This is a value to stand in for lots of unquantifiable stuff: strength of campaign, how well movies are liked by voters, and which films have made themselves look inevitable.
For each of the simulations, we mess with the baseline scores of each movie a little bit. This is basically adding in some baseline uncertainty into the scores, because we want to figure out the overall preferences of the Academy, but we also know that these are imperfect and don’t fully encapsulate the attitudes of the Academy as a whole. So even though A Star Is Born hasn't won a lot of prizes, we want to imagine at least a few scenarios where people like it way more, and less, than its current score illustrates. We want to induce uncertainty.
Each user also has a unique spin on the films. Maybe they worked on one, or work with a studio behind one of them, or simply enjoyed a film better. So we randomly simulate some favorability or unfavorability for each film for a given user.
But we also know that each of these films got nominated by these same people and starts from a baseline of favorability.
So every user has a score for each movie which (this year) ranges from at minimum 8 to at maximum 11.4. Check out the code for more on how we arrive there.
Simulate that voter’s ballot

Now we get to the actual “fill in the ballot” part, and as anyone who’s ever ranked stuff knows this isn’t as simple as A to Z. Again, just read any of those Oscar ballots revealed to understand the “nuance” or “absolute idiocy” that goes into why they’re ranked as they are. People rank the best movie first, or the movie they think will win first, or the movie their ex-boyfriend worked on last, or whatever. To accommodate this weighted randomness — and to illustrate how little this actually makes a difference in the end — basically we pick ranks dodgeball-style, randomly but based on those weights from the first step. So the highest-weighted movie isn’t guaranteed to come in first, it just has the best chance to come in first.
Do that 8,800 times to simulate the Academy ballot box

So those two steps are how we figure out each ballot for a single voter. There are 8,800-ish voters. All that they have in common each time is that they start from the same set of precursor weights: if in one simulation The Favourite’s chances are boosted, that’s the same for every voter. We simulate every vote and then move onto the next step.
(This step is simple, for now, but tweaking this a little bit can give us insight later on into the voting power of different blocs. For instance, I can adjust this part so that half the Academy likes one movie a lot more than the other half and we can see what changes. More on this next week.)
Figure out who wins that simulation based on the rank preference Algorithm

The ranked preference algorithm used by the Academy works like follows.
Count up the vote. Does any film have an explicit majority of top votes? If yes, that movie is the winner! If no, proceed to step two.
Find out which film got the least votes. That film is now eliminated from contention. Strike it from the ballots.
Take all the ballots that had the eliminated film as their top vote and redistribute them to their second favorite film.
Go back to step 1!
It’s a system that’s designed to find the film with the broadest appeal. Once we have that winning film, we record it. Thus we complete one simulation.
Do this 10,000 times. Report how many of those times each movie won

We do that process lot of times. Before we get into the outcomes of how many model runs each film won, I want to take a second and illustrate the true strength of the ranked ballot system. I wrote some code to track which film was a given user’s first choice each time in one of the model runs. This means that of the 8,800 ballots in the 10,000 model runs — 8.8 million simulated ballots — I kept track of how often a film got top ballot placement. Please ignore the stupid number of decimal places here, but take a look at how equally spread out these top votes are:

This makes intuitive sense: everyone has lots of favorite movies for lots of different reasons. But the ranked-choice algorithm turns this chaos into order quite handily. We did 10,000 simulations. Here’s how many times each film pulled ahead:
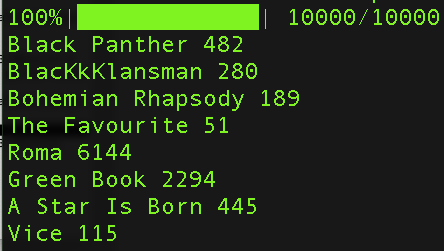
So Roma won about 6,100 times out of 10,000 times. Green Book won 2,300 times out of 10,000 times. Black Panther and A Star Is Born won just shy of 500 times each.
To turn these into percentages is left as an exercise for the reader. This was an attempt to figure out how the scores we’ve built would translate into victories under the Oscar voting procedures, not an attempt to put a percentage chance on the outcome. I’ve seen people get burned on this before.
Because again, this is an attempt to illustrate how the voting system would roll with these estimates of predictions. That The Favourite would win in only 51 of 10,000 possible scenarios isn’t a commentary on the film, it’s more saying that a film with The Favourite’s track record against films with the track records of Roma and Black Panther and Green Book would have to have been supremely underestimated by every precursor to be the real winner.
Steve Pond of The Wrap, who’s the best in the game at tracking the voters and constituencies of the Academy, illustrated some of the ways that ranked preference gets a better sense of the true preference in voting systems, if you want more reading on that.
This stacks up with previous years. Retroactively applying the model to previous years, last year’s winner The Shape of Water won in about 6,500 simulations compared to 1,900 simulations for Three Billboards. Three years ago, The Revenant was winning in 4,600 simulations, The Big Short was winning in 2,500 of them, and eventual winner Spotlight in 2,000 of them. And the biggest upset in recent Oscar memory also looks that way. Moonlight’s (700 simulated wins) surprise win over La La Land (7,900 simulated wins) underscores the nature of that upset. A movie with Moonlight’s track record at the precursors would generally face a lot of headwinds against a movie with La La Land’s track record. And Moonlight’s win was a canary in the coal mine for the changing Academy, and illustrated how significantly the precursors were not representing the Oscar race.
More coming up: tomorrow a President’s Day bonus post. Next week, final predictions and more.