

Numlock Awards: The 2022 Final Oscar Forecast
A note on the model and what it says about tonight.
Numlock Awards is your one-stop awards season newsletter. Every week, join Walt Hickey and Michael Domanico as they break down the math behind the Oscars and the best narratives going into film’s biggest night. Today’s edition comes from Walter.
We’re doing another post-Oscar mailbag! Send in questions by replying to this email. Got something you want to know, a tweet you’d like us to respond to, a question we haven’t addressed? Just reply to this email, or email awards@numlock.news.
When I first split off and redesigned this model, it was in response to a tectonic shift that was not being accounted for. The Academy had grown, and would continue to grow. Models are, simply, models, and when the entity upon which they’re based changes, the model must too. It’s why I maintained what was proven to work — the precursor awards reliably indicate some of the perceptions of the voters — but tweaked what no longer was working: evenly weighting data from each of the past 20 years was ignorant of the changes that were upon us, so it’s time to really significantly weight recent results.
It’s been good. I’ve been on balance happy with the results. But it could be better, and I know that, because I specifically designed this model to get better when it’s wrong. It rolls with the punches. The model has built-in potential.
Mainly, though, a good model also works when it fails, by telling you information about how the entity differs from the framework you have for it, and it adjusts. I think a model is useless if it’s a black box, if you don’t know exactly why it says what it’s going to say, if the input data isn’t revealed and it’s hawked as a party trick. When this model gets it wrong, we learn something. We learn how better to model the Academy’s preferences, we learn which wisdom is becoming antiquated, and which events are keeping pace with the explosive growth of the organization. It’s been nice to track that evolution over the past several years, and that’s made it worth the occasional misses.
That’s also why I’ve been a bit blasé about our Best Picture forecast. Way back in the 2018 Oscar Season, I laid the challenge out like this: imaging trying to predict a Senate election in Illinois if the entire population of Ohio moved to Illinois. Things have only gotten harder for us. At this point, it’s more like if the entire population of Florida moved to New York. This isn’t supposed to be easy; I’ve been thrilled the model’s held up as well as it has — the excellent track record in acting and directing has been edifying — and I’m mostly excited to get out of this holding pattern within a few years, when the Academy’s growth stabilizes.
That said, it’s why I think it’s reckless and naive to assign serious, hard probabilities to this kind of stuff. I think that overstates our confidence, and by a long shot. Election forecasts are based on hundreds if not thousands of polling observations, weather forecasts you’re talking about millions of variables pumped through supercomputers, sports models have dozens of games and thousands of plays, but with the Oscars we’re talking fewer than ten legitimate inputs. I try to keep it humble about what we can know and what we can’t know, and the system is too dynamic for anything more than baseline advice of who is competitive, and how competitive they look. Knowing how to model is less important than knowing when to model, which is why we don’t bother with the downballots; faux-certainty is an ugly look.
So, that brings us to the forecast. Think of this as the instruments on a plane, just something that you, the pilot, should account for, not the end all be all. Instruments can be wrong, but the information within them can be valuable.
The model gives an edge to The Power of the Dog in Best Picture, but it’s a tight race. This is not a runaway by any stretch. CODA is still in this. I would be very, very surprised if a movie that is not one of those wins — read my interview with Rob Ritchie last year, the expert on ranked-choice voting, to get why I say that.
It’s close. It’ll be a nail biter. Enjoy the show!

Everything else:


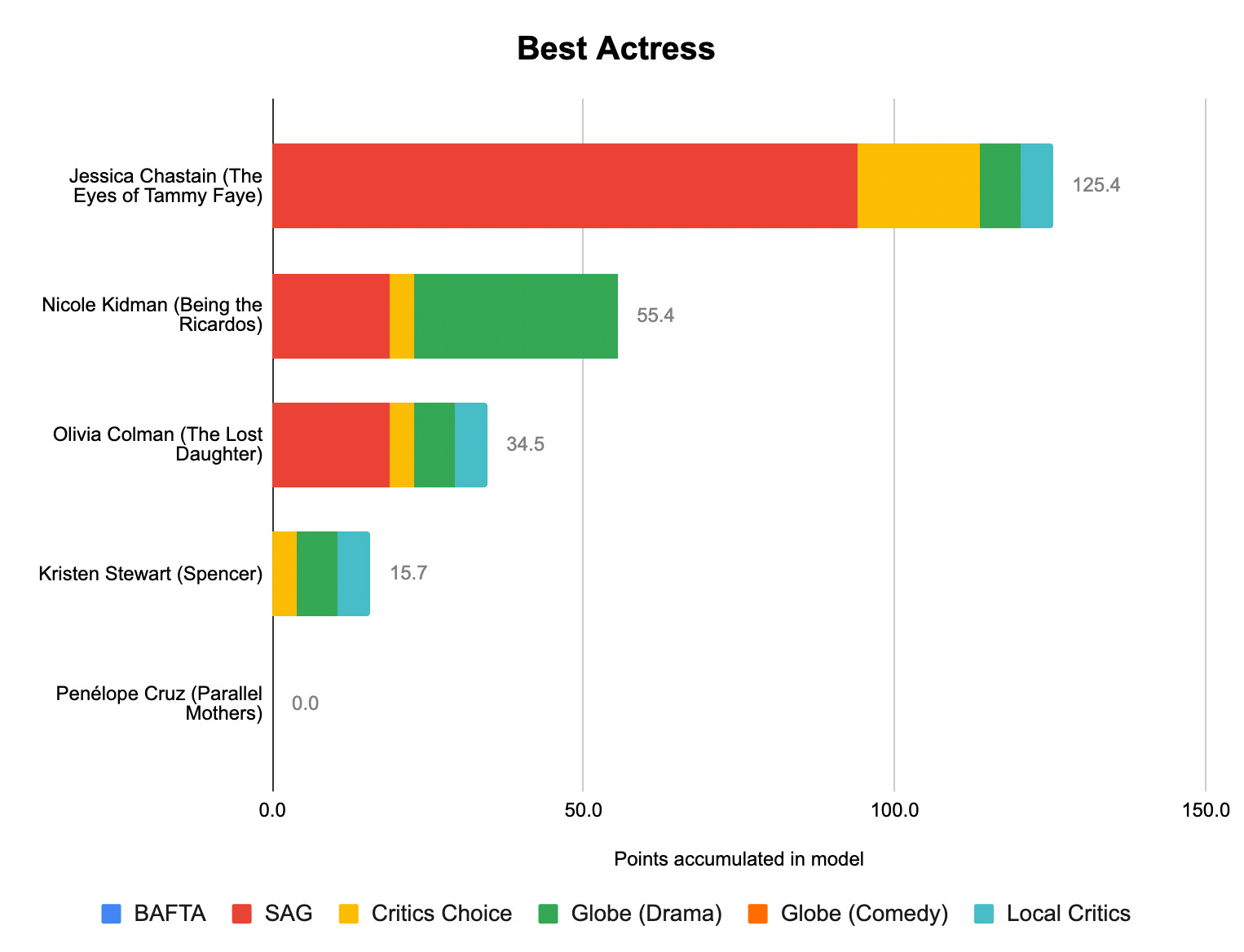
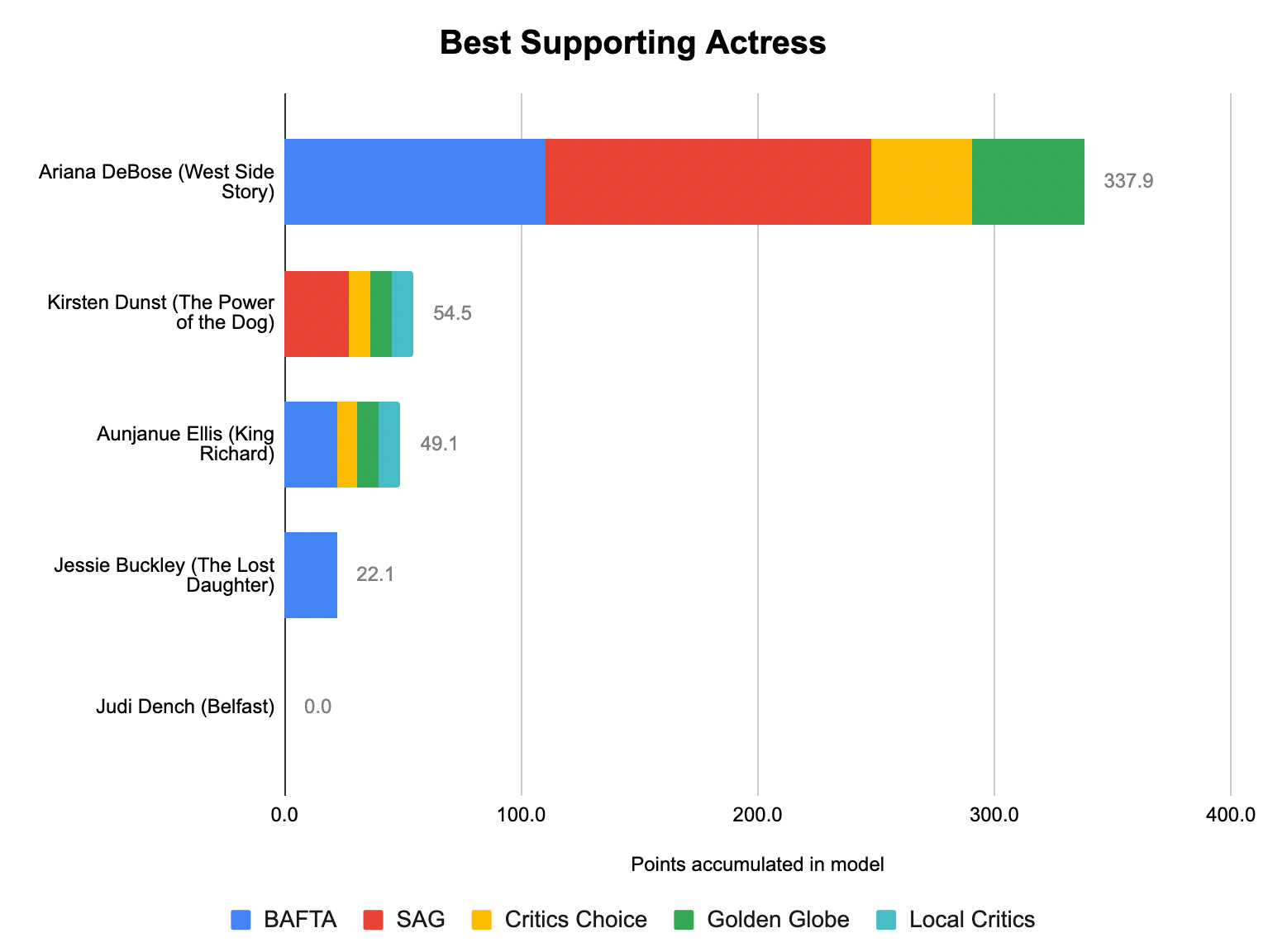
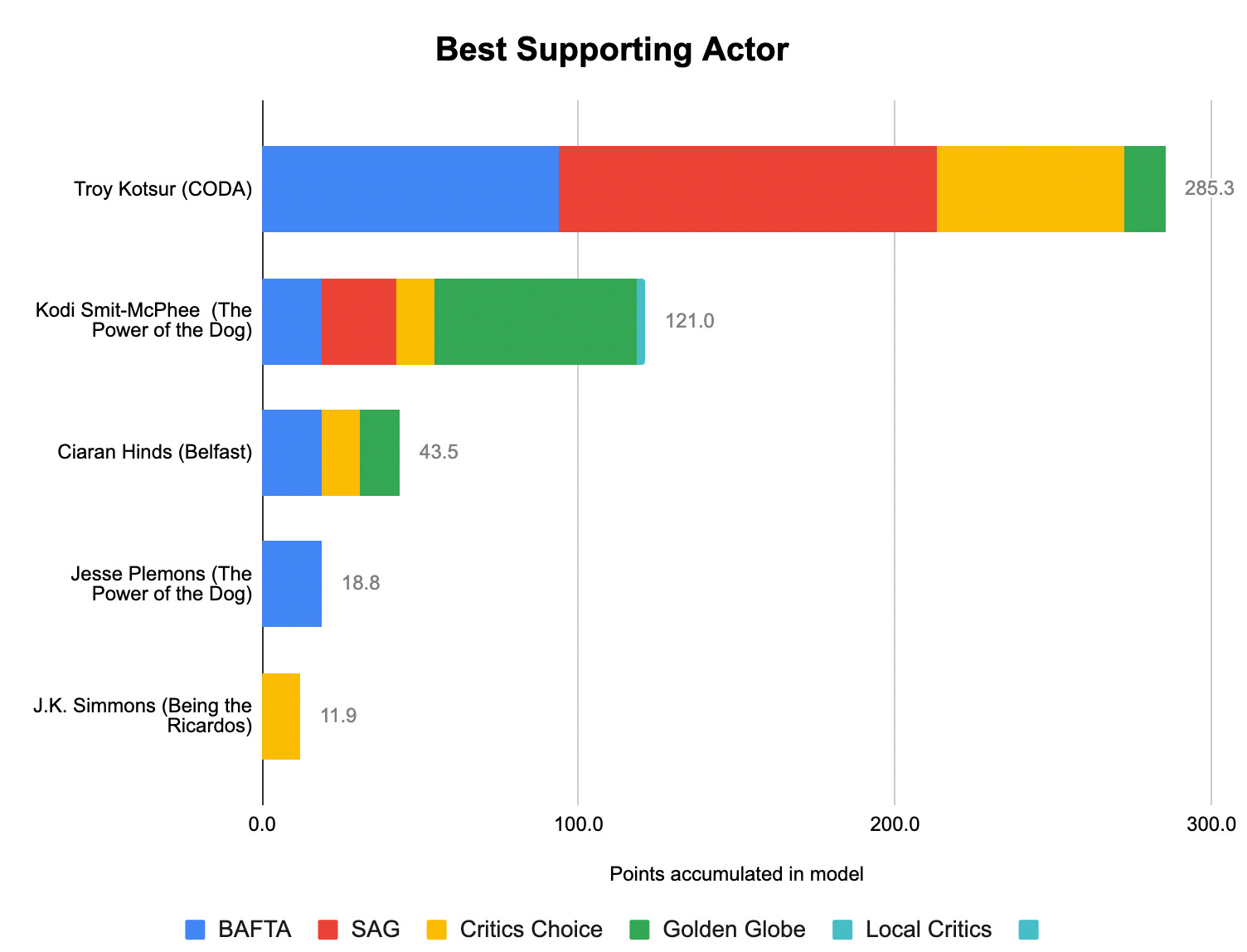
Thanks for reading! If you’re still hungry for more, I talked about some of our work this year with Harry Enten over at CNN and with Kai Ryssdal and Andie Corban over at Marketplace.
I’ve got one big data post coming next weekend and then the mailbag! Be sure to reply with a question you want us to hit.